
用 Numba 學 CUDA! 從入門到精通 (上)
/ 59 min read
–views Updated:Table of Contents
一起玩遊戲學習如何寫驅動 99% 深度學習的演算法 CUDA 的 Kernel 吧 🤩
本系列文將介紹如何使用 Numba 來進行 CUDA 編寫,因為篇幅關係,本文習題詳解只有到第 8 題,後續的詳解請參考:用 Numba 學 CUDA! 從入門到精通 (下)
2026/05/29:本來只是想從 Medium 搬過來,但發現實在有太多地方是第一版沒有說清楚的了,所以進行了大翻新,還加了兩張梗圖哦!!
前言
在學習深度學習的過程中,一定會常常看到 CUDA 這個名詞出現在各種環境設定與安裝的教學中,可以說是從旅程一開始就陪在我們身邊,但就像空氣一樣,即使知道它很重要,我們日常並不會深刻地感覺到它的存在。
這主要是因為各個深度學習框架都已經把這部分照顧好了 (見下圖),所以實務上很少有機會直接與它打交道:
隨著 LLM 與 Diffusion Model 等各類大型生成式模型的崛起 (還有 NVDA 的股價 📈),GPU 架構的重要性與日俱增,也該是時候學點 CUDA 了。
而要學習 CUDA 就不得不提到來自 Cornell Tech 及 Hugging Face 的大神 Sasha Rush (@srush_nlp) 開發 GPU Puzzles 解謎遊戲:
它提供互動式的謎題,讓我們能在實際撰寫 GPU 核心程式碼 (Kernel) 的同時學習 CUDA 的基本觀念,並且將結果視覺化,讓我們能更好的建立直覺。
更棒的是,它使用 Python 的 Numba 函式庫,所以不需要會寫 C 就能無痛獲取撰寫低階 CUDA 程式碼的體驗 (實際上,Numba 的寫法跟 C++ 的寫法很接近,然後本文的超連結我都有檢查過了,可以放心點開)。
而且這些謎題難度由簡入深,從熟悉基本概念到實作卷積運算,做完就能從完全不懂晉升到了解驅動當今 99% 深度學習的演算法在硬體加速層面是如何實現的!
看到這裡已經手癢癢躍躍欲試的小朋友可以直接跳去 GPU Puzzles 用 Colab 開起來挑戰看看了 (記得 Runtime 要使用 GPU)。
謎題完整的解答以及作者其它解題遊戲 (Tensor 與 Autodiff) 可以在我的 Repo 找到,解完也記得回來看看詳解哦。
但如果想在解題前先有一些基本知識,讓自己在解題時不要那麼霧裡看花的孩子就繼續看下去吧!
CUDA 小學堂
CUDA (全名是 Compute Unified Device Architecture,統一計算架構) 是由 NVIDIA 所推出的軟硬體整合技術,是該公司對於 GPGPU (General-purpose computing on GPUs) 的正式名稱。
它不僅定義了 GPGPU 的硬體架構,也定義了一套程式設計模型,讓我們能利用 NVIDIA 的 GPU 進行圖像處理以外的運算 (像是物理模擬、深度學習等😉)。
從程式開發者的角度來看,當我們以一般 C 語言撰寫程式時,程式碼通常只允許我們使用 CPU 來執行程式,如果想要利用 GPU 的話,傳統上必須使用較為複雜的繪圖應用程式介面 (API),例如 Direct3D 或 OpenGL。(哇,這句話提到程式的次數多到可以組一個社區了,這樣算不算一種 “區程式”)
而 CUDA 則提供了一套 C/C++ 延伸模組 (CUDA 也支援其它語言,但這裡以 C 舉例),讓開發者可以使用熟悉的語言來撰寫平行運算的程式 (Parallel programming),並且只需要 一個程式就能活用兩種硬體。
總的來說,CUDA 的程式碼一部分是一般的 C,用以控制 CPU,而另一部分是 C 的延伸模組 (強調平行化),用以控制 GPU。
在編譯時,CUDA 編譯器會將程式碼拆分開來,分別為不同硬體進行編譯。
混合運算模型 (Hybrid computing model)
為了充分利用我們擁有的運算資源,CUDA 採用混合運算模型的概念,在此概念中 CPU 與 GPU 會協同合作,將 CPU 不擅長的平行運算都交給專為此設計的 GPU。
在此模型中,我們會將 CPU 稱為 Host,GPU 則稱為 Device,它們各自擁有只有自己可以存取的記憶體空間,分別被稱為 Host memory 與 Device memory。
而 CUDA 程式的執行通常由以下幾個主要步驟組成:
- 配置 GPU 上的記憶體。
- 將輸入資料從 Host memory 複製到 Device memory。
- 載入 GPU 程式碼並執行。
- 將結果從 Device memory 複製回 Host memory。
其中第 3 步驟的程式碼又稱為 核心函式 (Kernel),是由 Host 發起並在 Device 上執行的 GPU 函式。
注意,這幾個步驟都是由 CPU 所發起的,這也是它被稱為 Host 的原因,作為整個運算的主要控制者,除了自己要執行的運算之外,還得準備要運算的資料以及將 Kernel 派送到 GPU 上執行,超級忙!
下圖中橘色文字即為 CPU 需要負責的部分,不管是收發資料還是配置記憶體,GPU 都只能被動地對 CPU 做出反應 (這只是比較基本的模型,GPU 其實不總是那麼被動,但這已經超過本文的範疇):
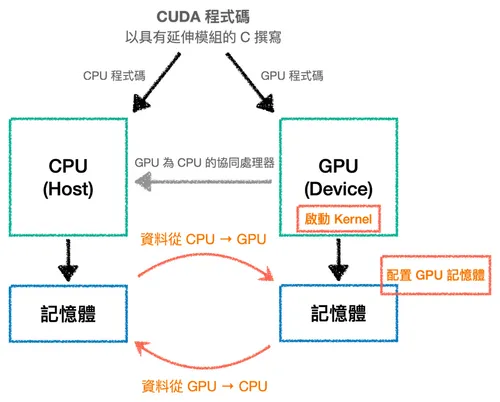
當然,在硬體間傳送資料一定會有代價,所以在設計程式時需要盡可能避免多次來回傳輸。
執行緒階層架構 (Thread hierarchy)
在上述的步驟中,移動資料跟配置記憶體相對簡單,真正有趣的地方在於撰寫 Kernel,這也是我們今天的主要目的,但在此之前,必須要再次強調 GPU 的特性是:
- 能有效率地啟動大量執行緒。
- 會平行地運行大量執行緒。
引用超級電腦之父 西摩·克雷 (Seymour Roger Cray) 的名言 —「如果你要耕一塊地,你願意用 2 頭牛還是 1024 隻小雞?」,先不管克雷原本覺得哪種比較好,GPU 就是我們的超多隻小雞!
這句話也點出了相較於 CPU,GPU 更著重於吞吐量 (Throughput),而非單一任務的延遲 (Latency)。
而這個特性進一步可以引申出平行運算的核心概念「把大問題拆成小問題,然後 同時 解決這些小問題」,而 CUDA 程式設計模型便將此概念總結為以下設計心法:
撰寫 Kernel 時,假裝它只會被一個執行緒運行 (按照一般序列式的寫法),等到從 CPU 派送 Kernel 時,再告訴它該啟動多少個執行緒,讓這些執行緒都執行這個 Kernel。
其中,程式的平行性實際上表現在了啟動執行緒的時候,至於是為什麼,就得從執行緒的階層架構開始說起,接下來就先從最底層開始依序介紹。
執行緒 (Threads)
最基本的部件,用以執行程式碼與儲存少量的狀態 (State),因此每個執行緒都具備固定大小的 區域記憶體 (Local memory) 供其調用。
為了更方便理解,我們將一個執行緒具現化為一個阿瑋 (不知道為什麼,就感覺挺適合的),而他能存取的區域記憶體則為一罐啤酒 (實務上一般使用 B̷a̷r̷ ̷b̷e̷e̷r̷):

區塊 (Blocks)
一群執行緒就稱為區塊,在程式上,它們代表的是一群通力合作解決一個子任務的執行緒。
其中最重要的一個細節是每個執行緒都能夠透過 CUDA 預先定義好的內建變數 (threadIdx) 知曉自己在 Block 中的位置。
如此一來,我們就能明確地為每個執行緒指派它該負責的部分,這就是前面所說「平行性表現在啟動執行緒時」的實際樣貌:一次啟動一大堆執行緒,再靠 threadIdx 讓每條執行緒各自認領不同的資料。

身為開發者,我們的任務就是適當定義區塊的大小,讓執行緒能一起合作完成運算。
但要注意,CUDA 會限制 每個區塊內 的執行緒數量 (目前多數 GPU 上每個區塊最多 1024 個),因此有時候會需要多個區塊才能完成運算。
事實上,CUDA 還支援了 2D 與 3D 區塊,下圖為 2D 區塊,其長寬就是這個區塊的大小:

而由於不同的執行緒間,通常都有共用資料的需求,因此住在同一個區塊的執行緒可以透過共享記憶體 (Shared memory) 進行交流。
並且只有該區塊中的執行緒才能讀取、寫入這塊固定大小的記憶體,我們可以把共享記憶體具現化為一手啤酒 (很荒謬,請忍耐一下):
網格 (Grids)
最後,多個區塊的組合就稱為網格 (同樣支援 1D、2D 與 3D 結構),其中每個區塊的大小都相同,且都有各自的共享記憶體:
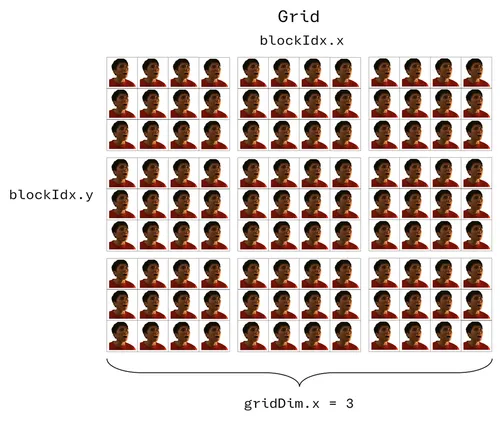
同樣地,為了要指派任務給特定的執行緒,我們必須知道它在網格中的位置,而且這個位置必須是網格中獨一無二的索引值,因此將計算方式定義如下 (假設我們要指定跟阿嬤頂嘴的橘衣阿瑋):

之所以將執行緒以網格、區塊這種多維度的方式組織起來,是因為遇到多維度問題時,這麼安排很方便、很直覺。
舉例來說,當我們想要處理一張 8×8 的圖片時,我們可以用一個 8 x 8 的 2D 區塊,讓每個執行緒負責一個像素,座標自然就對應上了。
當然,多維只是一種 “為了方便” 的組織方式,同樣的工作改用其他排列也能做到,只是這麼寫能讓演算法更直覺。
(嚴格來說,不同的排列方式確實會影響效能,這牽涉到 GPU 存取記憶體的方式,不過那已經超出本文範圍,讀者先有個 排列會影響效率 的印象就好。)
而且這個架構也能幫助我們把許多問題拆解成相對獨立的小問題:每個區塊負責處理整體問題的一部分,而區塊又把這部分再細分給內部的各個執行緒去做。
透過同一個區塊中所有執行緒都會執行同一份 Kernel 程式碼的平行性表現 (只是各自處理不同的資料),就能讓運算更快被完成,程式碼也更容易撰寫、理解與維護。
舉例來說,假設我們寫了一個負責 彬彬就是遜啦 的 Kernel,其執行起來效果就是這樣:

*Source: 超多阿瑋 在杰難逃!! 這次「杰哥」還有辦法得逞嗎?
GPU 與執行緒階層架構
事實上,執行緒的階層架構不僅僅是組織程式碼的方式,它同時也直接對應到硬體的運作方式,並讓平行運算能更有效率地執行。
在硬體上,GPU 是由多個 串流多處理器 (Streaming multiprocessor, SM) 所組成,通常越高階的 GPU 會有越多 SM。
當我們從 CPU 派送一個 Kernel 時,它會展開成一個由區塊 (Block) 組成的網格 (Grid),而 GPU 內部的排程器會負責把這些區塊 (Block) 分配給各個 SM。
一旦某個區塊被指派給某個 SM,就會在那裡待到結束、不會中途被搬到別的 SM。
另外,視區塊所需的硬體資源 (暫存器、共享記憶體等) 而定,單一個 SM 也可以同時收下好幾個區塊一起並行 (Concurrent) 處理。
而區塊被分配到 SM 之後,SM 又是怎麼實際 “跑” 裡頭的這些執行緒的呢?
實際上,SM 驅動執行緒時會以一組一組的 執行緒束 (Warp) 為單位 (而非逐一推動每個阿瑋,沒錯,我還沒忘記阿瑋就是執行緒這件事)。
目前 NVIDIA 的 GPU 上,每個 Warp 固定是 32 個執行緒。
講到這裡,Thread、Block、Grid、SM、Warp 這些角色都登場了。
現在我們就把「從 Kernel 啟動到執行緒實際開跑」這條流程用 “分進合擊” (Divide & Conquer) 的概念想像一遍,順道釐清每個角色的定位:
首先,Kernel 啟動時會召集一大票阿瑋執行緒入伍,以小隊 (Block) 為單位編成一支大軍 (Grid),其中每個阿瑋都清楚自己屬於哪一隊、又是隊裡的第幾個 (還記得 threadIdx 嗎)。
接著排程器把各支小隊分派到不同的據點 (SM),一個據點還能同時駐紮好幾支小隊,而真正開打時,每支小隊又會以 32 人為一班 (Warp),同一班的阿瑋會踏著相同的口令、同步做同一個動作,各自處理自己負責的那塊資料。
等所有人都完成手上的任務,這些散落各處的結果合起來,就是我們要的最終答案。
一拆 (Divide)、一算、一合 (Conquer),差不多就是 “分進合擊” 想傳達的精神。
而這套「一份命令、千軍同步執行」的運作方式,正是前面「撰寫 Kernel 時假裝只有一個執行緒在跑」這個心智模型能成立的硬體基礎:我們只需要考慮好一個阿瑋該做的事,硬體自然會讓一整班、一整隊、乃至一整支大軍的阿瑋以 Warp 為單位同步地把它跑過一遍。
這同時也呼應了我們一開始所講的「吞吐量重於延遲」。
一個 SM 通常會同時讓很多個 Warp 處於待命狀態,當某一班阿瑋卡住、得停下來等 (例如正在讀取較慢的記憶體) 時,排程器就立刻換上另一班準備好的阿瑋繼續做事,藉此把等待的時間 “藏” 起來,讓 SM 始終有事可做。
也就是說,GPU 並不追求把單一個阿瑋操得多快,而是仰仗著手上永遠有班可換、有事可做的大量 Warp,把整體的產出衝高,這就是 1024 隻小雞 (或者說 1024 個阿瑋) 的精神。
下圖為執行緒階層架構與 GPU 硬體資源的對應關係:
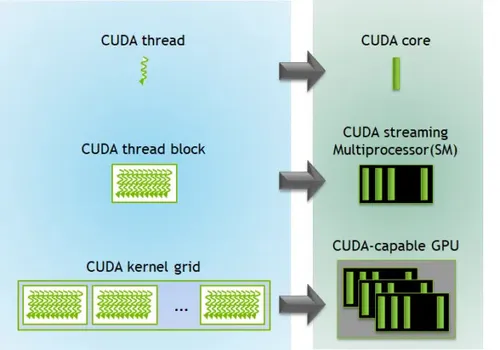
*Source: CUDA Refresher: The CUDA Programming Model
要注意的是,這張圖只是階層對應的示意圖,圖中把一個執行緒對到一個 CUDA 核心,並不代表執行緒和核心是靜態的一對一綁定。
回想前面的 Warp 機制就知道,實際上是大量執行緒被排程到 SM 上、以 Warp 為單位輪流換班執行,而非一條執行緒從頭到尾佔住一個核心。
好啦,了解 SM 實際怎麼執行 Kernel 之後,我們把視角拉遠一點,來看看這套以區塊為單位的組織方式還帶來了什麼好處。
其中的一個關鍵,就藏在前面我刻意略過不提的一個細節裡:區塊被分配到哪個 SM、以什麼順序執行,其實都是無法保證的。
正因為沒有把任何區塊綁死在特定的執行順序或硬體上,這套組織方式才換來了強大的可擴縮性 (Scalability),讓我們在不修改程式碼的情況下,就能自動適應不同算力的硬體。
以下圖為例,同樣一支含有 8 個區塊的程式,在只有 4 個 SM 的小 GPU 上,每個 SM 就得各自輪流負責兩個區塊;但換到擁有 8 個 SM 的大 GPU 上,每個 SM 只要負責一個區塊,整體速度就輕鬆快了一倍。
重點是,這整個過程全交由 GPU 自行調度,我們一行程式碼都不用碰:
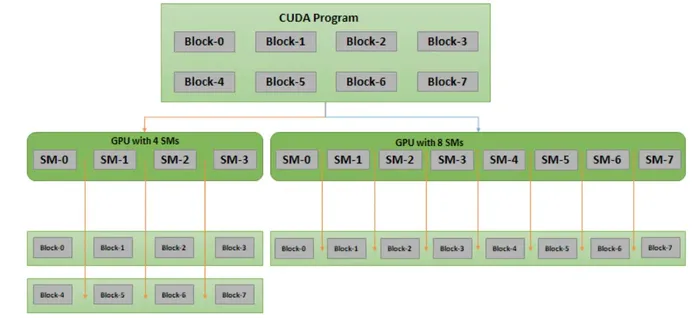
*Source: CUDA Refresher: Getting started with CUDA
最後,除了前面提到的區域記憶體與區塊共享記憶體之外,還有一種記憶體是不論哪個區塊的執行緒都能存取的,我們稱之為 全域記憶體 (Global memory)。
而這三種記憶體,其實都能對應到 GPU 上實際的硬體:
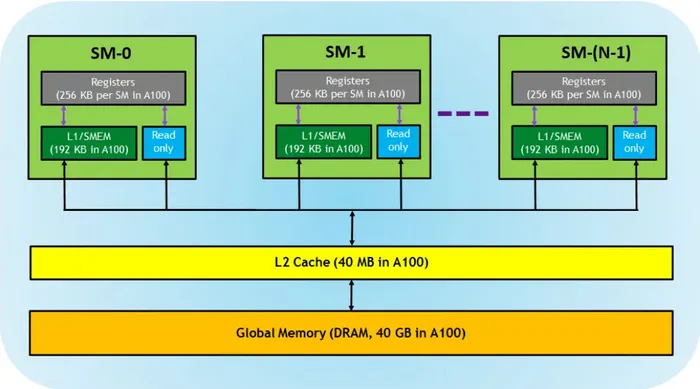
*Source: CUDA Refresher: The CUDA Programming Model
- 暫存器 (Registers):對應到區域記憶體,是每個執行緒私有、速度最快的儲存空間,由編譯器決定如何最佳化使用。
- L1/共享記憶體 (SMEM):對應到區塊共享記憶體,位於每個 SM 上 (on-chip),因此速度快,可同時作為 L1 快取與共享記憶體,由同一個 SM 上的所有區塊共用。
- 全域記憶體 (Global memory):即 GPU 上的 DRAM,容量大但速度相對最慢,所有執行緒都能存取。
由此可見,越靠近執行緒、私有程度越高的記憶體通常越快,但容量也越小;反之容量越大的越慢。
因此,縱使 CUDA 編譯器已經會自動最佳化記憶體的使用,開發者若能順著這個階層、把握 資料盡量待在快的記憶體裡 的原則,通常還能進一步壓榨出更好的效能。
而具體該怎麼避免資料在不同記憶體間移動所帶來的開銷 (Overhead),就是我們接下來在實作中會慢慢體會的事了。
Numba 與 CUDA 程式設計模型
前面提到,我們將使用 Numba 函式庫來學習 CUDA,它在語法上與 CUDA C 非常接近,卻多了 Python 的可讀性,而且用 Numba 寫的 Kernel 可以直接存取 NumPy array (表面上看是如此,實際上 Numba 會在背後自動幫我們把 Array 在 CPU 與 GPU 之間搬移,除非我們手動控制)。
但要注意,Numba 底層是把 Python 程式碼直接編譯成符合 CUDA 執行模型的 Kernel 與裝置函式 (Device function),因此 並非所有 Python 語法都能被轉換。
最常見的一條限制是:由於 GPU 不適合在 Kernel 裡動態配置記憶體,凡是 “會臨時生出一塊新空間” 的寫法通常都不支援,例如 List comprehension (會生出一個新的 list),或是會回傳新陣列的 NumPy 操作。
換句話說,如果遇到編譯錯誤,十之八九是程式碼寫得太 “花俏” 了,把每個執行緒的工作壓到最樸素的讀幾個值、算一算、寫回去,通常就沒事了。
完整的支援清單可參考 Supported Python features in CUDA Python。
概念性的東西已經講得夠多了,下面就來介紹幾個最基本的寫法。
執行緒的位置
當執行 Kernel 時,其程式碼會被每個執行緒各執行一次,因此每個執行緒都必須知道「自己是誰」,才能算出它該負責哪些陣列元素。
而我們可以使用 numba.cuda 提供的幾個變數來推算執行緒的位置 (這些變數都藏在前面介紹執行緒階層架構的附圖中了,看名稱就能猜到意思):
from numba import cuda
# 這裡只示範位置計算,省略了裝飾器與完整結構def kernel(): x = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x y = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y算法挺直覺的,這裡再一次請出頂嘴阿瑋:
撰寫 Kernel
複習一下,Kernel 是從 CPU 呼叫、在 GPU 上執行的函式,這個特性使得 Kernel 不能顯式地回傳數值:所有運算結果都必須寫進 作為引數傳入的陣列 裡,就算結果只是一個純量,也得用一個單元素陣列來接住它。
而在撰寫時,只需要把符合此特性的 Python 函式加上 @cuda.jit 裝飾器即可 (若是裝置函式,要再加上 device=True):
from numba import cudaimport numpy as npimport numba
# 裝置函式 (device function),供 Kernel 內部呼叫@cuda.jit(device=True)def add(a, b): return a + b
@cuda.jitdef my_func(inp, out): # 注意:這裡刻意用上區域記憶體與裝置函式,純粹是為了一次展示這些寫法, # 單純做加 10 其實用不到它們 # 宣告一塊每個執行緒私有的區域記憶體 (要指定大小與型別) local = cuda.local.array(5, numba.float32)
# 找出自己的位置 x = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x y = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
# 守門員:避免存取超出陣列範圍的位置 if x < out.shape[0] and y < out.shape[1]: # 在區域記憶體裡放一個值 local[1] = 10 # 透過裝置函式相加,再寫回全域記憶體 out[x, y] = add(inp[x, y], local[1])啟動 (Launch) Kernel
要注意的是,我們無法直接呼叫 my_func,而是需要先準備好資料、設定好 block 與 grid 的形狀,再啟動它:
# 準備輸入與輸出陣列 (這裡的形狀只是示範用,挑多大都行,# 超出範圍的部分會由 Kernel 裡的守門員 (guard) 自動略過)inp = np.arange(4 * 4, dtype=np.float32).reshape(4, 4)out = np.zeros_like(inp)
# 設定 grid 與 blockthreadsperblock = (4, 3) # 每個區塊 4×3 個執行緒blockspergrid = (1, 3) # 每個網格 1×3 個區塊
# 啟動 Kernelmy_func[blockspergrid, threadsperblock](inp, out)
print(out) # 每個元素都會是 inp 對應位置 + 10這真的已經很接近 CUDA C 的寫法了,同樣的東西在 C 裡會寫成 my_func<<<blockspergrid, threadsperblock>>>(inp, out)。
我們可以把這裡拆成兩個步驟:
- Kernel 實例化:透過指定每個網格有幾個區塊、以及每個區塊有幾個執行緒,來把編譯好的 Kernel 實例化,兩者乘積就是執行緒的總數。
注意 Kernel 一旦編譯完成,就能以不同的執行緒階層架構被重複實例化、呼叫多次。 - 執行 Kernel:以輸入陣列作為引數來執行 Kernel (視情況再加上輸出陣列)。
注意 Kernel 是 非同步 (Asynchronous) 執行的,呼叫後會馬上回傳,因此若需要等它跑完,得呼叫cuda.synchronize()來等待。
總結以上的說明,再次提醒讀者,CUDA 的程式設計有以下幾個要點:
- 撰寫 Kernel 時,我們先假設程式只會在單一個執行緒上執行。
- 接著可以視需要啟動大量執行緒來跑這個 Kernel,但注意每個區塊的執行緒數有上限 (前面提過,目前多數 GPU 上是 1024),不過可以靠增加區塊數量把總量堆上去。
- 每個執行緒都知道自己在網格中的位置。
以上就是讓讀者聞香一下,實際上這些語法已經足夠我們完成謎題,其它關於 Numba 更詳細的說明,請參考 NUMBA CUDA Guide。
GPU 謎題
首先我們以第一題為例,介紹謎題程式碼的大致架構,它主要由三個部分組成:

xxx_spec(…):範例,等同於前面講的「先假設只在單一個執行緒上執行」的程式碼,也是我們希望 Kernel 做的事,但這部分只是提示,不能直接呼叫!xxx_test(cuda):答題區域,裡頭會有一些先寫好的程式碼,我們只需要在# FILL ME IN下方填上答案即可。- 其餘部分:負責定義 Block、執行 Kernel 並將結果視覺化,這部分不需要改動。
而視覺化會提供兩項資訊供我們解題:
- 記憶體讀寫次數:
這裡會顯示每個執行緒對全域記憶體與共享記憶體的讀寫次數。
由於全域記憶體是容量大但速度較慢的外接記憶體 (off-chip),存取時還有額外的開銷,速度比不上共享記憶體這類較快的內建記憶體 (on-chip),所以答題時提供這個資訊,供我們權衡兩類記憶體的使用:

記憶體讀寫報告 - 執行緒的溝通模式視覺化:
平行程式設計的關鍵在於執行緒間的協同合作,而正如人與人之間的相處,良好的協作仰賴於溝通 (Communication)。
在 CUDA 中,這樣的溝通就發生在記憶體裡,因此寫一支 CUDA 程式,基本上就是在設計「任務 (執行緒) 與記憶體之間的對應關係」。
白話說,就是決定每個執行緒要讀哪些資料、寫到哪裡去,以及怎麼做得有效率。
題目已經幫我們定義好執行緒階層架構,並畫成漂亮的彩虹小圈圈 (建議每次動手寫之前先執行一次,就能看到執行緒階層架構與輸入、輸出的對應圖像):
執行緒溝通模式視覺化
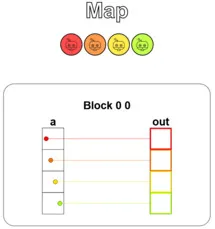
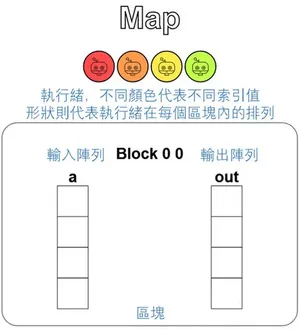
Puzzle 1 — Map
好啦,我們就開始來熱身吧,這一題會稍微把整個 Cell 講得詳細一點,但之後的題目就只會專注在 xxx_test(cuda) 囉。
題目要我們實作一個將向量 a 每個位置都加 10 的 Kernel,並將結果寫入 out 向量,除此之外,題目還額外提供了兩個資訊:
- 提醒我們只能使用基本的 Python 語法 (加減乘除、陣列索引、for 迴圈與 if-else 條件子句等)。
- 資料量與執行緒數量相同 (You have 1 thread per position.)。
第一點是為了避開前面所說的 Python 語法轉換限制;第二點則要跟題目附的小訣竅和完整程式碼一起看才有意思。
先看完整的 Cell:
def map_spec(a): return a + 10
def map_test(cuda): def call(out, a) -> None: local_i = cuda.threadIdx.x # FILL ME IN (roughly 1 lines)
return call
SIZE = 4out = np.zeros((SIZE,))a = np.arange(SIZE)
problem = CudaProblem( "Map", map_test, [a], out, threadsperblock=Coord(SIZE, 1), spec=map_spec)
problem.show()其中,最下面的 CudaProblem 只是這個習題框架提供的 helper,幫我們把 Kernel 包好、執行、再把結果視覺化,細節可以忽略,唯一需要注意的是 threadsperblock=Coord(SIZE, 1) 這一個引數。
它把區塊設定為 SIZE × 1 = 4 個執行緒,剛好對應輸入向量 a 與輸出向量 out 的形狀 (SIZE,),也就是「每個位置一個執行緒」。
接著看題目的小訣竅:「想像每個執行緒都會執行一次 call 函式,唯一不同的只有每次 cuda.threadIdx.x 都會改變。」
這其實就是前面那個「撰寫 Kernel 時假裝只有一個執行緒在跑」的心智模型,而這套運作方式在 GPU 領域有個我一直沒講的正式名稱叫做 SIMT (Single Instruction, Multiple Threads)。
恭喜,您又多學了一個名詞 🎉
像這樣「每個執行緒獨立負責一個位置,做完同一件事就寫回去」的模式,就是平行運算中最基本的 Map (輸入和輸出之間是 1 對 1,彼此完全不干擾)。
這是 GPU 非常擅長的模式,解答也很簡單,只需要把 threadIdx.x 同時拿來當作輸入與輸出的索引值就好:
def map_test(cuda): def call(out, a) -> None: local_i = cuda.threadIdx.x # FILL ME IN (roughly 1 lines) out[local_i] = a[local_i] + 10 return call執行結果如下圖,可以看到每個執行緒 (以顏色做區分) 都從輸入向量 a 中取一個元素,加上 10 後寫進輸出向量 out:
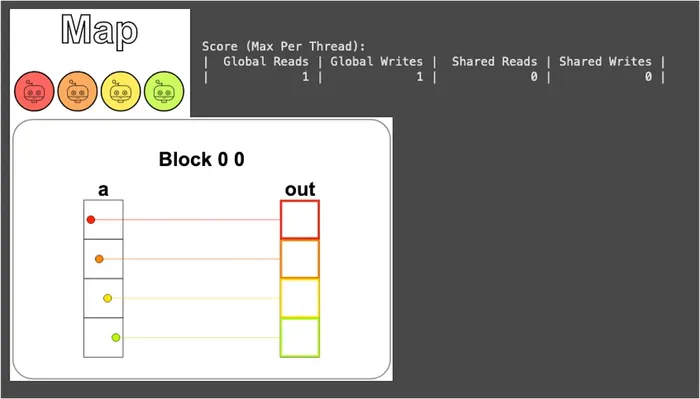
這裡值得再停下來釐清一下:a 和 out 原本是 Host (CPU) 上的 NumPy array,但 CudaProblem 在背後幫我們把它們搬到了 GPU 上,所以 Kernel 裡的 a[local_i]、out[local_i] = ... 實際上都是在跟全域記憶體打交道,也就回到前面說的「Numba 會在背後自動幫我們把 Array 在 CPU 與 GPU 之間搬移」這件事。
另外,因為資料和執行緒是 1 對 1 對應,每個執行緒都只需要負責把自己那個位置讀一次、算一算、寫一次就能完成所有運算,因此全域記憶體的讀和寫都各只有 1 次,不能再更少了。
而 “讀寫次數” 之所以值得在意,是因為前面提過全域記憶體比共享記憶體慢得多,能少碰一次就少一次:

接著執行 problem.check() 就能看到通過後的可愛狗狗 GIF:

阿!如果寫錯就會看到我們的輸出以及正確答案應該長怎樣:
Puzzle 2 — Zip
題目要我們實作一個將向量 a 與 b 每個位置都相加、再把結果寫進 out 向量的 Kernel,就像把拉鍊兩端的齒一一對齊扣起來一樣,因此這個操作被稱為 Zip。
跟第一題比起來,題目的設定其實只多了一個變化:輸入從一個變成兩個,但資料量依然與執行緒數量相同,所以「每個位置由一個執行緒負責」這個對應關係沒變。
換句話說,這題本質上還是 Map 的精神,只是這次每個執行緒要從兩個地方各取一個值來相加而已:
def zip_test(cuda): def call(out, a, b) -> None: local_i = cuda.threadIdx.x # FILL ME IN (roughly 1 lines) out[local_i] = a[local_i] + b[local_i] return call執行結果如下圖:
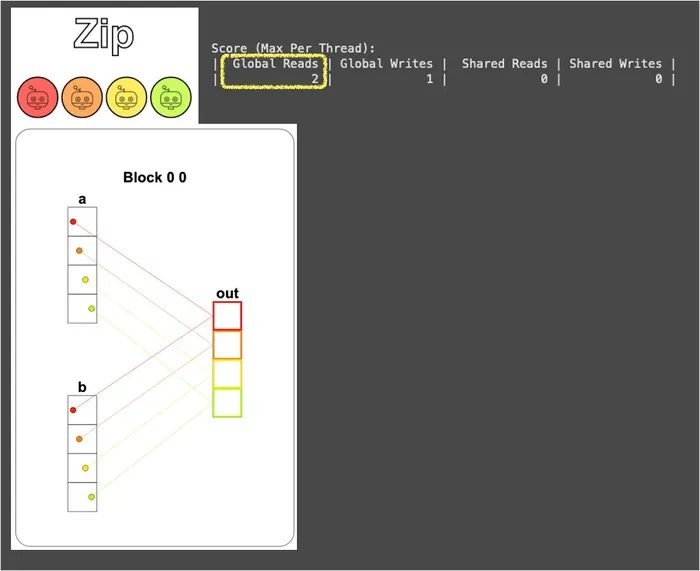
可以看到每個執行緒都會分別從 a 和 b 各取一個元素相加 (a[local_i]、b[local_i]),所以全域記憶體會被讀 2 次、寫 1 次 (比 Map 多了一次讀取)。
而 “2 讀 1 寫” 就是 Zip 模式的代價:每多一個輸入向量,每條執行緒就得多跑一趟全域記憶體,當輸入有 N 個向量時,全域讀取就會是 N 次。
這對 Zip 這種簡單情境影響不大,但之後遇到資料會被重複用到的題目時,每次都老老實實去全域記憶體拿就會變得很奢侈,這是伏筆,記好啦!
Puzzle 3 — Guards
這題跟第一題一樣,要實作把向量 a 每個位置都加 10、再寫進 out 向量的 Kernel,但 這次執行緒數量比資料量還多。
別小看這個差別,這其實才更貼近真實情況,因為區塊內的執行緒數通常是固定挑好的 (而且還偏好 32 的倍數,這跟前面講的 Warp 有關),而資料量本來就不會剛好配合我們,因此執行緒比資料多一點點幾乎是常態。
而當執行緒比資料多的時候,就得小心讓每筆資料都只由一個執行緒負責就好,不要讓多出來的執行緒拿著超出範圍的 local_i 去做 out[local_i] = ...,在 Python 裡 Numba 還會給出 IndexError: index 4 is out of bounds for axis 0 with size 4 來阻止我們,但在真實的 CUDA/C 環境裡可沒人攔你,那些越界的寫入會直接落到別人的記憶體上,是真的會出事的。
當然,也不是說 threadIdx 大於 size 的執行緒就一定不能用,硬要派工作給它們也行,只是這樣一來我們就得另外設計索引、把它們的 local_i 轉換回 size 範圍內的合法位置才行,有點太過反人類了:

所以最直覺、也最省事的做法就是用一個條件子句把超出範圍的執行緒擋掉,讓它們什麼都別做就好,這個小條件就稱為 守門員 (Guard):
def map_guard_test(cuda): def call(out, a, size) -> None: local_i = cuda.threadIdx.x # FILL ME IN (roughly 2 lines) if local_i < size: out[local_i] = a[local_i] + 10 return call從視覺化結果可以看到我們只用了前 4 個執行緒,後 4 個乖乖待著什麼都不動:
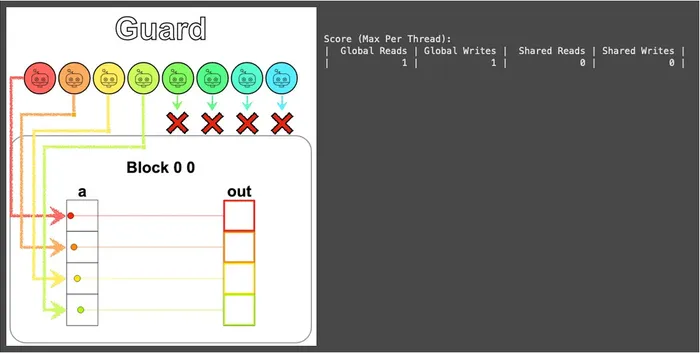
別小看這一個小小的 if,從這題開始它幾乎會出現在後面每一題裡,只要執行緒和資料對不齊,Guard 拿出來就對了。

Puzzle 4 — Map 2D
這題是上一題的 2D 版本,因為我們的資料變成二維了,所以區塊最好也跟著安排成二維,這樣每筆資料就能很直覺地用 (i, j) 兩個維度的索引去對應,Guard 的寫法也順其自然就好。
這裡題目設計很貼心地想要讓我們複習「執行緒總是會比資料多一些」這件事,所以設定成了 2×2 的資料配上 3×3 的執行緒,但我想這樣鐵定是難不倒聰明的讀者的:
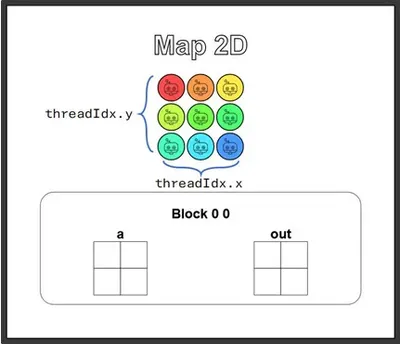
def map_2D_test(cuda): def call(out, a, size) -> None: local_i = cuda.threadIdx.x local_j = cuda.threadIdx.y # FILL ME IN (roughly 2 lines) if local_i < size and local_j < size: out[local_i, local_j] = a[local_i, local_j] + 10 return call跟 1D 版本比起來,程式碼基本上只是多了一個 local_j,Guard 也跟著多一個條件 (local_i 和 local_j 都得在範圍內)。
存取陣列就照 NumPy 習慣 my_array[i, j] 來,沒什麼新奇的東西。
視覺化結果如下:
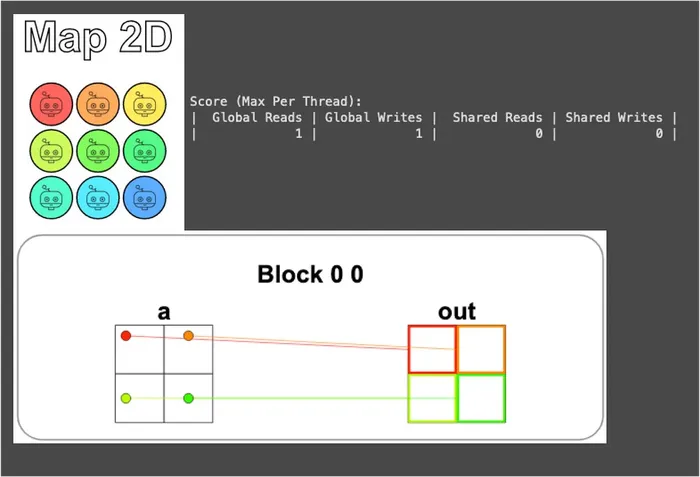
可以看到只有左上角的 4 個執行緒真的有做事,其它 5 個被 Guard 擋掉,乖乖待著不動,跟上一題 1D Guard 的精神一模一樣,只是擴展到了二維。
Puzzle 5 — Broadcast
這題跟第二題 Zip 很類似,都是要把兩個輸入向量相加,差別在於這次兩個輸入的尺寸不一樣,必須用 Broadcast 的方式對齊後再相加:
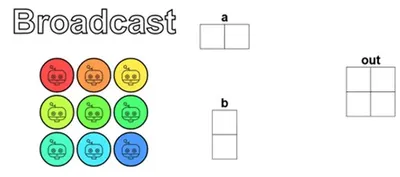
題目同樣用了 2×2 的資料配上 3×3 的執行緒,所以「執行緒比資料多」這件事跟上一題一樣,Guard 也是照搬就行,這部分我們已經很熟悉了。
真正要動腦的是怎麼把 a 跟 b 的元素 對應到正確的輸出位置。
從上圖可以看到,a 是沿著 x 軸鋪開的橫躺向量、b 是沿著 y 軸鋪開的直立向量,所以對於負責 out[i, j] 的執行緒來說,它需要的就是 a 在 x 軸位置 i 的值 (a[i, 0]) 加上 b 在 y 軸位置 j 的值 (b[0, j]):
def broadcast_test(cuda): def call(out, a, b, size) -> None: local_i = cuda.threadIdx.x local_j = cuda.threadIdx.y # FILL ME IN (roughly 2 lines) if local_i < size and local_j < size: out[local_i, local_j] = a[local_i, 0] + b[0, local_j] return call視覺化結果如下:
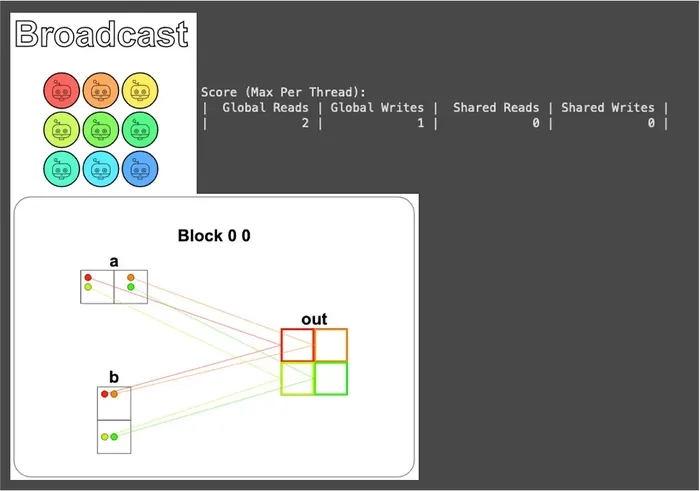
從讀寫報告上可以看到,每個執行緒讀 2 次、寫 1 次,跟 Zip 一模一樣,這是因為每個執行緒做的事差不多,都是從兩個地方拿值、加起來、寫回去。
但從圖中還能看到一件有趣的事:a 的每個元素都被 兩個不同的執行緒重複讀 了 (b 也一樣)。
以 a[0, 0] 為例,它同時被負責 out[0, 0] 和 out[0, 1] 這兩個不同執行緒各讀過一次。
報告中的 “讀 2 次” 是站在單一執行緒的角度算的,所以這個重複代價並不會顯現在那個數字上,但它確實存在,而且只要 SIZE 一變大就會跟著被等比放大 (SIZE × SIZE 個輸出,輸入卻只有 SIZE + SIZE 筆)。
還記得 Puzzle 2 結尾埋的伏筆嗎?那時候講的其實是「每個執行緒讀寫幾次」這一個層面,但這一題又多加上了「同一筆資料被多少執行緒重複拿」這一層。
兩層加在一起,就是後面要靠共享記憶體解決的痛點,但這部分要等到 Puzzle 8 才會揭曉,我們再讓子彈飛一會兒。
Puzzle 6 — Blocks
還記得前面學過「每個區塊最多只能有 1024 個執行緒」嗎?這題就是要讓我們練習當資料量大到一個區塊塞不下時該怎麼辦。
這一題給了 9 筆資料,但一個區塊只配了 4 個執行緒,所以勢必得動用多個區塊來增加可用的執行緒數量,才能把資料處理完。
這也是為什麼這題叫 Blocks,因為從這裡開始,我們就不再像前五題那樣只在一個區塊內玩耍,而是要真正用到「多區塊」這個概念啦!
從題目下面的 CudaProblem 可以看到,這次多了 blockspergrid=Coord(3, 1) 這個引數,也就是 每個 Grid 配 3 個區塊,等於總共會有 3 × 4 = 12 個執行緒在待命。
這個數字比 9 筆資料多出了 3 個,所以 Guard 在這題依然不能少。
另外,因為要跨區塊,所以每個執行緒就不能再只看 threadIdx.x 了 (因為每個區塊內的 threadIdx.x 都會從 0 重新數一遍),必須改用在前面已經示範過的全域索引公式:
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x(這條公式就是頂嘴阿瑋當初教我們的那條 😉)
把全域索引和 Guard 合起來,答案就出來了:
def map_block_test(cuda): def call(out, a, size) -> None: i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x # FILL ME IN (roughly 2 lines) if i < size: out[i] = a[i] + 10 return call視覺化結果如下:
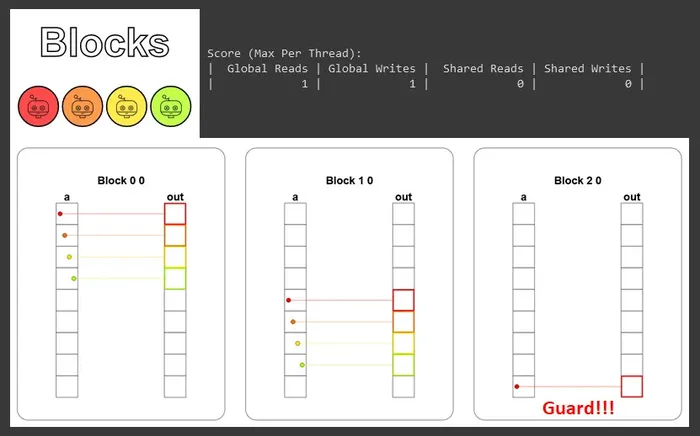
可以看到 3 個區塊各自吃下一段連續的元素 (區塊 0 負責 03、區塊 1 負責 47、區塊 2 負責 8),彼此不重疊也不互相打擾,最後一個區塊用 Guard 把多出來的執行緒擋掉。
而這也是 GPU 真正開始發力的時候:這些區塊會被派到不同的 SM 上 同時開跑,而不是一個跑完再輪到下一個跑。
從概念上來看,這裡就是前面所講的 “分進合擊”,以區塊為單位把大問題拆成小問題,每個區塊獨立解掉自己那塊,合起來就是完整答案。
Puzzle 7 — Blocks 2D
這題把上一題拓展到了 2D,也是最貼近實際應用的情境 (圖像、矩陣這些常見的資料本來就是二維的),但概念上跟 Puzzle 6 一模一樣,只是再加一個維度而已。
解法也很直覺,兩個維度都套全域索引公式,Guard 也跟著多一個條件:
def map_block2D_test(cuda): def call(out, a, size) -> None: i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x # FILL ME IN (roughly 4 lines) j = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y if i < size and j < size: out[i, j] = a[i, j] + 10 return call視覺化結果如下,可以很清楚看到我們是怎麼用區塊把一個大矩陣切成幾個小矩陣分頭處理,也能看到 Guard 是怎麼把超出範圍的執行緒擋掉的:
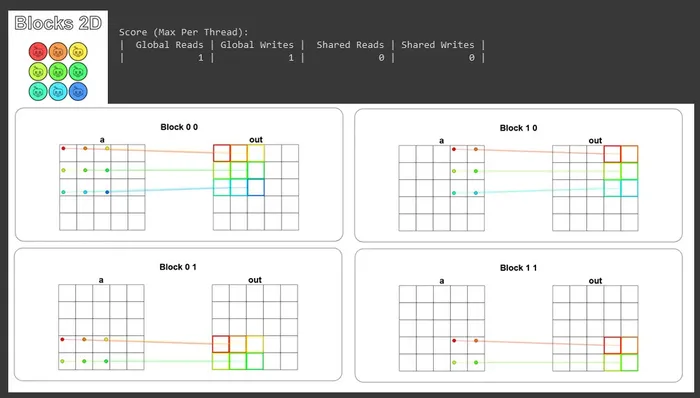
到這裡我們其實已經把 CUDA 的基本程式設計模型走過一輪了,執行緒、區塊、網格、Guard、全域索引、多區塊的分進合擊。
下一題開始,真正的好戲才要登場:共享記憶體。
Puzzle 8 — Shared
走到這裡,我們已經學會了執行緒怎麼運作、執行緒階層架構又是怎麼讓我們把資訊從輸入映射到輸出。
但仔細想想,我們對「區塊」的著墨其實還很淺,頂多就是拿它來算索引值而已,從這題開始,我們要解鎖區塊真正的實力:共享記憶體 (Shared memory)!
它的主要功用是讓同一個區塊內的所有執行緒可以互相交流,在硬體上,它和 L1 快取共用同一塊高速的內建記憶體 (on-chip),差別在於 L1 由硬體自動管理,而共享記憶體則可以由我們手動掌控。
所以當 Kernel 需要反覆讀取某些資料時,我們就能先把它們從全域記憶體搬進共享記憶體,省去像 Puzzle 5 那樣一再從全域記憶體重讀的成本,對效能會有顯著幫助。
但使用上要注意一點,共享記憶體真的很小,因為它是每個 SM 上要分給上頭所有區塊共用的高速記憶體,容量通常只有數十到一兩百 KB 等級 (例如 A100 每個 SM 約 192 KB、Colab 常見的 T4 約 64 KB),所以要省著用。
另外,因為多個執行緒會同時讀寫同一塊記憶體,資料競爭 (Race condition) 是難以避免的,因此需要在以下兩個時機呼叫 cuda.syncthreads() 進行同步:
- 資料載入共享記憶體後 — 等所有執行緒都把該載的東西載完,確保所有執行緒拿到的資料是一致的,才不會站在不同基準點進行後續運算。
- 計算結果寫回全域記憶體前 — 等所有執行緒都完成計算,確保結果不會被遺漏或覆蓋掉。
了解這些之後就可以動手了:
# 每個區塊內的執行緒數量TPB = 4
def shared_test(cuda): def call(out, a, size) -> None: # 宣告要使用的共享記憶體大小與型別,我們這裡小心翼翼的使用 16 bytes shared = cuda.shared.array(TPB, numba.float32) # 全域索引值,負責將資料寫入正確的輸出位置 i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x # 區塊內的執行緒索引值,負責對應到共享記憶體裡的位置 local_i = cuda.threadIdx.x
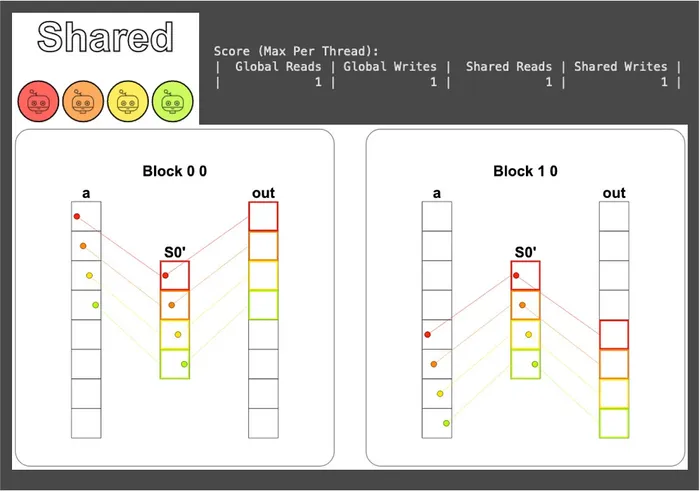
# Guard if i < size: # 將資料從全域記憶體中載入共享記憶體 shared[local_i] = a[i] cuda.syncthreads() # FILL ME IN (roughly 2 lines) # 這裡直接從共享記憶體讀完就寫回全域記憶體,沒有後續運算會用到 shared,所以不用再同步 out[i] = shared[local_i] + 10 return call從視覺化可以看到資料先被搬進了共享記憶體,經過一輪同步再被寫回全域記憶體;共享記憶體的讀寫各只有 1 次 (讀寫順序剛好和全域記憶體相反):
因為篇幅關係 (再寫下去就太長啦),本文習題詳解先到此告一段落,後續的詳解請參考:用 Numba 學 CUDA! 從入門到精通 (下)
那我們就到下一篇見啦~